spring5 源码深度解析----- IOC 之 默认标签解析(下)
正文
在spring源码深度解析— IOC 之 默认标签解析(上)中我们已经完成了从xml配置文件到BeanDefinition的转换,转换后的实例是GenericBeanDefinition的实例。本文主要来看看标签解析剩余部分及BeanDefinition的注册。
默认标签中的自定义标签解析
在上篇博文中我们已经分析了对于默认标签的解析,我们继续看戏之前的代码,如下图片中有一个方法:delegate.decorateBeanDefinitionIfRequired(ele, bdHolder)

这个方法的作用是什么呢?首先我们看下这种场景,如下配置文件:
<bean id="demo" class="com.chenhao.spring.MyTestBean">
<property name="beanName" value="bean demo1"/>
<meta key="demo" value="demo"/>
<mybean:username="mybean"/>
</bean>
这个配置文件中有个自定义的标签,decorateBeanDefinitionIfRequired方法就是用来处理这种情况的,其中的null是用来传递父级BeanDefinition的,我们进入到其方法体:

public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder definitionHolder) { return decorateBeanDefinitionIfRequired(ele, definitionHolder, null); } public BeanDefinitionHolder decorateBeanDefinitionIfRequired( Element ele, BeanDefinitionHolder definitionHolder, @Nullable BeanDefinition containingBd) { BeanDefinitionHolder finalDefinition = definitionHolder; // Decorate based on custom attributes first. NamedNodeMap attributes = ele.getAttributes(); for (int i = 0; i < attributes.getLength(); i++) { Node node = attributes.item(i); finalDefinition = decorateIfRequired(node, finalDefinition, containingBd); } // Decorate based on custom nested elements. NodeList children = ele.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { Node node = children.item(i); if (node.getNodeType() == Node.ELEMENT_NODE) { finalDefinition = decorateIfRequired(node, finalDefinition, containingBd); } } return finalDefinition; }
我们看到上面的代码有两个遍历操作,一个是用于对所有的属性进行遍历处理,另一个是对所有的子节点进行处理,两个遍历操作都用到了decorateIfRequired(node, finalDefinition, containingBd);方法,我们继续跟踪代码,进入方法体:
public BeanDefinitionHolder decorateIfRequired( Node node, BeanDefinitionHolder originalDef, @Nullable BeanDefinition containingBd) { // 获取自定义标签的命名空间 String namespaceUri = getNamespaceURI(node); // 过滤掉默认命名标签 if (namespaceUri != null && !isDefaultNamespace(namespaceUri)) { // 获取相应的处理器 NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri); if (handler != null) { // 进行装饰处理 BeanDefinitionHolder decorated = handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd)); if (decorated != null) { return decorated; } } else if (namespaceUri.startsWith("http://www.springframework.org/")) { error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node); } else { if (logger.isDebugEnabled()) { logger.debug("No Spring NamespaceHandler found for XML schema namespace [" + namespaceUri + "]"); } } } return originalDef; } public String getNamespaceURI(Node node) { return node.getNamespaceURI(); } public boolean isDefaultNamespace(@Nullable String namespaceUri) { //BEANS_NAMESPACE_URI = "http://www.springframework.org/schema/beans"; return (!StringUtils.hasLength(namespaceUri) || BEANS_NAMESPACE_URI.equals(namespaceUri)); }
首先获取自定义标签的命名空间,如果不是默认的命名空间则根据该命名空间获取相应的处理器,最后调用处理器的 decorate() 进行装饰处理。具体的装饰过程这里不进行讲述,在后面分析自定义标签时会做详细说明。
注册解析的BeanDefinition
对于配置文件,解析和装饰完成之后,对于得到的beanDefinition已经可以满足后续的使用要求了,还剩下注册,也就是processBeanDefinition函数中的BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder,getReaderContext().getRegistry())代码的解析了。进入方法体:
public static void registerBeanDefinition( BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) throws BeanDefinitionStoreException { // Register bean definition under primary name. //使用beanName做唯一标识注册 String beanName = definitionHolder.getBeanName(); registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition()); // Register aliases for bean name, if any. //注册所有的别名 String[] aliases = definitionHolder.getAliases(); if (aliases != null) { for (String alias : aliases) { registry.registerAlias(beanName, alias); } } }
从上面的代码我们看到是用了beanName作为唯一标示进行注册的,然后注册了所有的别名aliase。而beanDefinition最终都是注册到BeanDefinitionRegistry中,接下来我们具体看下注册流程。
通过beanName注册BeanDefinition
在spring中除了使用beanName作为key将BeanDefinition放入Map中还做了其他一些事情,我们看下方法registerBeanDefinition代码,BeanDefinitionRegistry是一个接口,他有三个实现类,DefaultListableBeanFactory、SimpleBeanDefinitionRegistry、GenericApplicationContext,其中SimpleBeanDefinitionRegistry非常简单,而GenericApplicationContext最终也是使用的DefaultListableBeanFactory中的实现方法,我们看下代码:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException { // 校验 beanName 与 beanDefinition Assert.hasText(beanName, "Bean name must not be empty"); Assert.notNull(beanDefinition, "BeanDefinition must not be null"); if (beanDefinition instanceof AbstractBeanDefinition) { try { // 校验 BeanDefinition // 这是注册前的最后一次校验了,主要是对属性 methodOverrides 进行校验 ((AbstractBeanDefinition) beanDefinition).validate(); } catch (BeanDefinitionValidationException ex) { throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName, "Validation of bean definition failed", ex); } } BeanDefinition oldBeanDefinition; // 从缓存中获取指定 beanName 的 BeanDefinition oldBeanDefinition = this.beanDefinitionMap.get(beanName); /** * 如果存在 */ if (oldBeanDefinition != null) { // 如果存在但是不允许覆盖,抛出异常 if (!isAllowBeanDefinitionOverriding()) { throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName, "Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName + "': There is already [" + oldBeanDefinition + "] bound."); } // else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) { // e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE if (this.logger.isWarnEnabled()) { this.logger.warn("Overriding user-defined bean definition for bean '" + beanName + "' with a framework-generated bean definition: replacing [" + oldBeanDefinition + "] with [" + beanDefinition + "]"); } } // 覆盖 beanDefinition 与 被覆盖的 beanDefinition 不是同类 else if (!beanDefinition.equals(oldBeanDefinition)) { if (this.logger.isInfoEnabled()) { this.logger.info("Overriding bean definition for bean '" + beanName + "' with a different definition: replacing [" + oldBeanDefinition + "] with [" + beanDefinition + "]"); } } else { if (this.logger.isDebugEnabled()) { this.logger.debug("Overriding bean definition for bean '" + beanName + "' with an equivalent definition: replacing [" + oldBeanDefinition + "] with [" + beanDefinition + "]"); } } // 允许覆盖,直接覆盖原有的 BeanDefinition this.beanDefinitionMap.put(beanName, beanDefinition); } /** * 不存在 */ else { // 检测创建 Bean 阶段是否已经开启,如果开启了则需要对 beanDefinitionMap 进行并发控制 if (hasBeanCreationStarted()) { // beanDefinitionMap 为全局变量,避免并发情况 synchronized (this.beanDefinitionMap) { // this.beanDefinitionMap.put(beanName, beanDefinition); List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1); updatedDefinitions.addAll(this.beanDefinitionNames); updatedDefinitions.add(beanName); this.beanDefinitionNames = updatedDefinitions; if (this.manualSingletonNames.contains(beanName)) { Set<String> updatedSingletons = new LinkedHashSet<>(this.manualSingletonNames); updatedSingletons.remove(beanName); this.manualSingletonNames = updatedSingletons; } } } else { // 不会存在并发情况,直接设置 this.beanDefinitionMap.put(beanName, beanDefinition); this.beanDefinitionNames.add(beanName); this.manualSingletonNames.remove(beanName); } this.frozenBeanDefinitionNames = null; } if (oldBeanDefinition != null || containsSingleton(beanName)) { // 重新设置 beanName 对应的缓存 resetBeanDefinition(beanName); } }
处理过程如下:
- 首先 BeanDefinition 进行校验,该校验也是注册过程中的最后一次校验了,主要是对 AbstractBeanDefinition 的 methodOverrides 属性进行校验
- 根据 beanName 从缓存中获取 BeanDefinition,如果缓存中存在,则根据 allowBeanDefinitionOverriding 标志来判断是否允许覆盖,如果允许则直接覆盖,否则抛出 BeanDefinitionStoreException 异常
- 若缓存中没有指定 beanName 的 BeanDefinition,则判断当前阶段是否已经开始了 Bean 的创建阶段(),如果是,则需要对 beanDefinitionMap 进行加锁控制并发问题,否则直接设置即可。对于
hasBeanCreationStarted()方法后续做详细介绍,这里不过多阐述。 - 若缓存中存在该 beanName 或者 单利 bean 集合中存在该 beanName,则调用
resetBeanDefinition()重置 BeanDefinition 缓存。
其实整段代码的核心就在于 this.beanDefinitionMap.put(beanName, beanDefinition); 。BeanDefinition 的缓存也不是神奇的东西,就是定义 一个 ConcurrentHashMap,key 为 beanName,value 为 BeanDefinition。
通过别名注册BeanDefinition
通过别名注册BeanDefinition最终是在SimpleBeanDefinitionRegistry中实现的,我们看下代码:
public void registerAlias(String name, String alias) { Assert.hasText(name, "'name' must not be empty"); Assert.hasText(alias, "'alias' must not be empty"); synchronized (this.aliasMap) { if (alias.equals(name)) { this.aliasMap.remove(alias); } else { String registeredName = this.aliasMap.get(alias); if (registeredName != null) { if (registeredName.equals(name)) { // An existing alias - no need to re-register return; } if (!allowAliasOverriding()) { throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" + name + "': It is already registered for name '" + registeredName + "'."); } } //当A->B存在时,若再次出现A->C->B时候则会抛出异常。 checkForAliasCircle(name, alias); this.aliasMap.put(alias, name); } } }
上述代码的流程总结如下:
(1)alias与beanName相同情况处理,若alias与beanName并名称相同则不需要处理并删除原有的alias
(2)alias覆盖处理。若aliasName已经使用并已经指向了另一beanName则需要用户的设置进行处理
(3)alias循环检查,当A->B存在时,若再次出现A->C->B时候则会抛出异常。
alias标签的解析
对应bean标签的解析是最核心的功能,对于alias、import、beans标签的解析都是基于bean标签解析的,接下来我就分析下alias标签的解析。我们回到 parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate)方法,继续看下方法体,如下图所示:
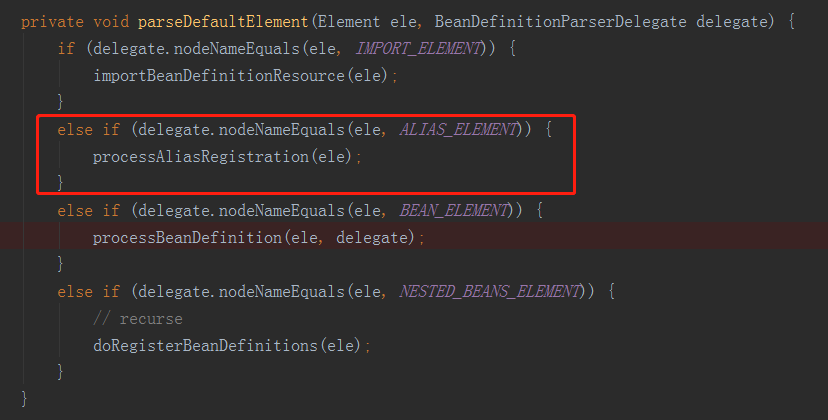
对bean进行定义时,除了用id来 指定名称外,为了提供多个名称,可以使用alias标签来指定。而所有这些名称都指向同一个bean。在XML配置文件中,可用单独的元素来完成bean别名的定义。我们可以直接使用bean标签中的name属性,如下:
<bean id="demo" class="com.chenhao.spring.MyTestBean" name="demo1,demo2">
<property name="beanName" value="bean demo1"/>
</bean>
在Spring还有另外一种声明别名的方式:
<bean id="myTestBean" class="com.chenhao.spring.MyTestBean"/>
<alias name="myTestBean" alias="testBean1,testBean2"/>
我们具体看下alias标签的解析过程,解析使用的方法processAliasRegistration(ele),方法体如下:
protected void processAliasRegistration(Element ele) { //获取beanName String name = ele.getAttribute(NAME_ATTRIBUTE); //获取alias String alias = ele.getAttribute(ALIAS_ATTRIBUTE); boolean valid = true; if (!StringUtils.hasText(name)) { getReaderContext().error("Name must not be empty", ele); valid = false; } if (!StringUtils.hasText(alias)) { getReaderContext().error("Alias must not be empty", ele); valid = false; } if (valid) { try { //注册alias getReaderContext().getRegistry().registerAlias(name, alias); } catch (Exception ex) { getReaderContext().error("Failed to register alias '" + alias + "' for bean with name '" + name + "'", ele, ex); } getReaderContext().fireAliasRegistered(name, alias, extractSource(ele)); } }
通过代码可以发现解析流程与bean中的alias解析大同小异,都是讲beanName与别名alias组成一对注册到registry中。跟踪代码最终使用了SimpleAliasRegistry中的registerAlias(String name, String alias)方法
import标签的解析
对于Spring配置文件的编写,经历过大型项目的人都知道,里面有太多的配置文件了。基本采用的方式都是分模块,分模块的方式很多,使用import就是其中一种,例如我们可以构造这样的Spring配置文件:
<?xml version="1.0" encoding="UTF-8" ?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <bean id="demo" class="com.chenhao.spring.MyTestBean" name="demo1,demo2"> <property name="beanName" value="bean demo1"/> </bean> <import resource="lookup-method.xml"/> <import resource="replaced-method.xml"/> </beans>
applicationContext.xml文件中使用import方式导入有模块配置文件,以后若有新模块的加入,那就可以简单修改这个文件了。这样大大简化了配置后期维护的复杂度,并使配置模块化,易于管理。我们来看看Spring是如何解析import配置文件的呢。解析import标签使用的是importBeanDefinitionResource(ele),进入方法体:
protected void importBeanDefinitionResource(Element ele) { // 获取 resource 的属性值 String location = ele.getAttribute(RESOURCE_ATTRIBUTE); // 为空,直接退出 if (!StringUtils.hasText(location)) { getReaderContext().error("Resource location must not be empty", ele); return; } // 解析系统属性,格式如 :"${user.dir}" location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location); Set<Resource> actualResources = new LinkedHashSet<>(4); // 判断 location 是相对路径还是绝对路径 boolean absoluteLocation = false; try { absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute(); } catch (URISyntaxException ex) { // cannot convert to an URI, considering the location relative // unless it is the well-known Spring prefix "classpath*:" } // 绝对路径 if (absoluteLocation) { try { // 直接根据地址加载相应的配置文件 int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources); if (logger.isDebugEnabled()) { logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]"); } } catch (BeanDefinitionStoreException ex) { getReaderContext().error( "Failed to import bean definitions from URL location [" + location + "]", ele, ex); } } else { // 相对路径则根据相应的地址计算出绝对路径地址 try { int importCount; Resource relativeResource = getReaderContext().getResource().createRelative(location); if (relativeResource.exists()) { importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource); actualResources.add(relativeResource); } else { String baseLocation = getReaderContext().getResource().getURL().toString(); importCount = getReaderContext().getReader().loadBeanDefinitions( StringUtils.applyRelativePath(baseLocation, location), actualResources); } if (logger.isDebugEnabled()) { logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]"); } } catch (IOException ex) { getReaderContext().error("Failed to resolve current resource location", ele, ex); } catch (BeanDefinitionStoreException ex) { getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]", ele, ex); } } // 解析成功后,进行监听器激活处理 Resource[] actResArray = actualResources.toArray(new Resource[0]); getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele)); }
解析 import 过程较为清晰,整个过程如下:
- 获取 source 属性的值,该值表示资源的路径
- 解析路径中的系统属性,如”${user.dir}”
- 判断资源路径 location 是绝对路径还是相对路径
- 如果是绝对路径,则调递归调用 Bean 的解析过程,进行另一次的解析
- 如果是相对路径,则先计算出绝对路径得到 Resource,然后进行解析
- 通知监听器,完成解析
判断路径
方法通过以下方法来判断 location 是为相对路径还是绝对路径:
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
判断绝对路径的规则如下:
- 以 classpath*: 或者 classpath: 开头为绝对路径
- 能够通过该 location 构建出
java.net.URL为绝对路径 - 根据 location 构造
java.net.URI判断调用isAbsolute()判断是否为绝对路径
如果 location 为绝对路径则调用 loadBeanDefinitions(),该方法在 AbstractBeanDefinitionReader 中定义。
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException { ResourceLoader resourceLoader = getResourceLoader(); if (resourceLoader == null) { throw new BeanDefinitionStoreException( "Cannot import bean definitions from location [" + location + "]: no ResourceLoader available"); } if (resourceLoader instanceof ResourcePatternResolver) { // Resource pattern matching available. try { Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location); int loadCount = loadBeanDefinitions(resources); if (actualResources != null) { for (Resource resource : resources) { actualResources.add(resource); } } if (logger.isDebugEnabled()) { logger.debug("Loaded " + loadCount + " bean definitions from location pattern [" + location + "]"); } return loadCount; } catch (IOException ex) { throw new BeanDefinitionStoreException( "Could not resolve bean definition resource pattern [" + location + "]", ex); } } else { // Can only load single resources by absolute URL. Resource resource = resourceLoader.getResource(location); int loadCount = loadBeanDefinitions(resource); if (actualResources != null) { actualResources.add(resource); } if (logger.isDebugEnabled()) { logger.debug("Loaded " + loadCount + " bean definitions from location [" + location + "]"); } return loadCount; } }
整个逻辑比较简单,首先获取 ResourceLoader,然后根据不同的 ResourceLoader 执行不同的逻辑,主要是可能存在多个 Resource,但是最终都会回归到 XmlBeanDefinitionReader.loadBeanDefinitions() ,所以这是一个递归的过程。
至此,import 标签解析完毕,整个过程比较清晰明了:获取 source 属性值,得到正确的资源路径,然后调用 loadBeanDefinitions() 方法进行递归的 BeanDefinition 加载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号