从 CNN 性能优化说起(一)

对于做深度学习系统的行内人来说,CNN 的性能优化是一个老话题。但是新人仍然经常震撼于一个事实 —— 手写一个 convolution layer 的七层循环和Caffe的实现相比,性能差距100多倍。
本文详解贾杨清于2014年写了一篇简短的 memo,描述了他的通过把 CNN 变成矩阵乘的加速方法 https://github.com/Yangqing/caffe/wiki/Convolution-in-Caffe:-a-memo 。这个被扬清谦虚地称为“临时方案”的做法被后来的各种深度学习框架复现,甚至影响了深度学习编译器的研究。
本文复用了一篇很不错但读者不多的英语博客中的叙事顺序和图示;其原文在 https://sahnimanas.github.io/post/anatomy-of-a-high-performance-convolution ,并且修正了一些借用的图示。此外,本文增加对 convolution 计算过程的介绍,以承上。并且简单介绍 TVM 和 MLIR 背后的思路,以启下。
Convolution 的计算过程
先得知道 convolution layer 的计算过程才好优化。Convolution layer 对一幅图像 A 做 convolution,结果输出为图像 B。所谓的 convolution 操作是指给定一个 K x K 的小矩阵(kernel),把图 A 中每个 K x K 个像素构成的小片(patch)中的每个像素值乘以 kernel 中对应的数值,然后所有乘积加起来,作为图像 B 中一个像素的值。大致过程如下图。其中左边的大矩阵是图像 A,右边的大矩阵是图像 B,中间的 3x3 的小矩阵是 kenel。


细心的读者会发现,如果kernel是3x3的,那么图像A的最外边一圈像素没有图像B中对应的像素。确实如此。如果kernel是5x5的,那么图像B的大小相当于图像A除去最外边两圈的像素。类似的,如果kernel是7x7的,则失去了最外边三圈的像素。如果想要B和A一样大,可以在A外边加上几圈值为0的像素。这个操作叫做 padding。类似专门用于 convolution 的操作还有 striding。文本不细说了。(本文假设 striding 都是 1。)
实际上一副图像可能有多个 channels。比如彩色图像通常有 RGB 三个channel。实际操作里,经常是图像A有 Ca 个 channels,而每个 kernel 是 Ca x K x K 的一个立方体 —— 这里请注意,kernel 的 channel 数和图像 A 的一样,都是 Ca。这样,广义的 convolution 是大小为 CaxKxK 的 patch 和同样大小的 kernel 做 element-wise 乘,然后结果相加,成为B中的一个像素。这样 B 的 channel 数是 1。
进一步泛化,我们可以假设有 Cb 个大小为 Ca x K x K 的 filters 参与 convolution 计算。这样得到的图像 B 的 channel 就是 Cb 了。这个泛化在深度学习里很常见。因为网络里经常有连续多层 CNN layers,每层的输入和输出的 channels 数都大于 1。
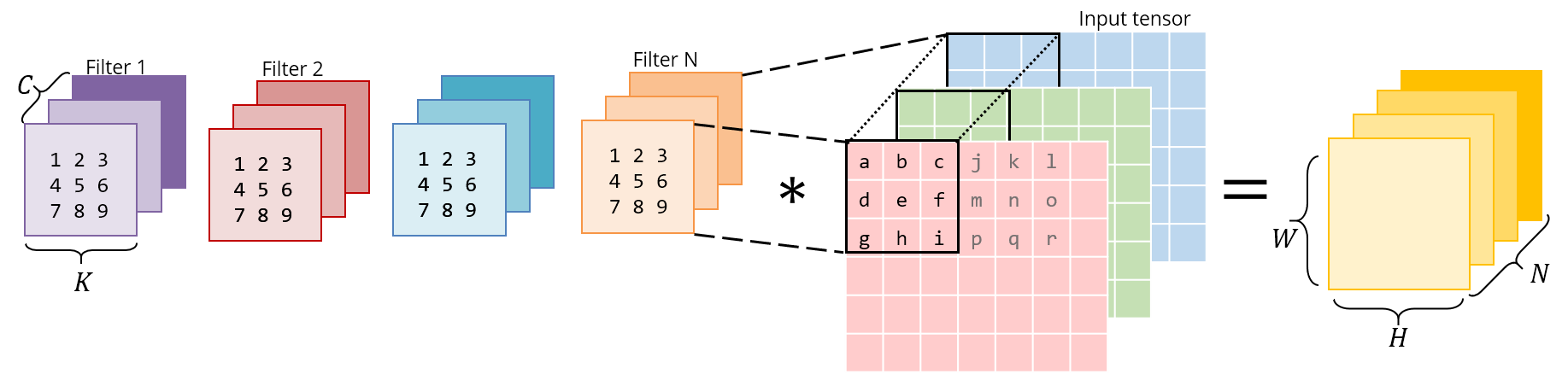

Convolution Layer 的土鳖实现
接下来我们尝试手写一个 convolution layer。这里图像A的大小是 Ca x Ha x Wa,其中 H 和 W 表示高度和宽度。图像 B 的大小是 Cb x Hb x Wb。而 kernel 的大小是 Cb x Ca x K x K。实际上 kernel 的宽度和高度可以不等,这里为了简单,取常见情况,姑且假设 kernel 是正方形的吧。另外,每个 minibatch 假设有 N 张图。
for n in 0..N
for cb in 0..Cb
for ca in 0..Ca
for hb in 0..Hb
for wb in 0..Hb
for hk in 0..K
for wk in 0..K
B[cb, hb, wb] +=
kernel[cb, ca, hk, wk] *
A[ca, hb + hk, wb + wk]可以看到这里需要一个 7 层循环!按照 https://sahnimanas.github.io/post/anatomy-of-a-high-performance-convolution 的记录,即使用 C 写,-O3 加上 -Ofast,对于 CIFAR10 数据集,每个 minibath 里的每张图需要 2.2 秒。而 Caffe 的实现只需要 18ms。差距 100 多倍。如果不开编译优化,则差距是 1000 多倍。
贾杨清的加速法
扬清在 Caffe 的 memo 里记录的方法是把图像 A 里的每个 patch 都展开成一个向量,然后把所有向量拼成一个大矩阵 A'。类似的,把 Cb 个 kernel 也展开成一个大矩阵 K'。则 convolution 就可以变成这两个矩阵相乘 A' x K'。得到的大矩阵就是 B。


仔细对比上面两幅图就可以看出扬清从图像 A 构造矩阵 A' 的方法。他的 memo 是从这样的构型导致内存增加说起的。确实,图像 A 里的一个像素会重复多次出现在 A' 里。比如上图展示标记为 c 的像素出现了 3 次。最多会重复出现多少次呢?比如 i,出现了 K x K 次。不过,这样的内存增长带来的是性能的 100 倍甚至 1000 倍的提升。
几乎每一种 CPU 或者 GPU 的开发商都会提供 BLAS 基本函数库的实现。BLAS 里有一个泛化矩阵乘函数 GEMM,可以算 p A B + q C。可以通过把 q 和 C 设置为 0,p 设置成标量 1,让 GEMM 来计算两个矩阵 A 和 B 的乘积。正是通过使用 Intel 提供的 GEMM 来计算 A' K' 得到了 100 倍的速度提升。
小结
那么 GEMM 的开发者到底做了什么呢?K x K 倍的内存消耗可否避免呢?请听下文分解。
