内容简介:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
贝叶斯定理
已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为: 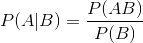
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面直接给出贝叶斯定理:
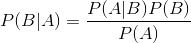
package com.immooc.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.classification.NaiveBayes
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.{SparkConf, SparkContext}
object NaiveBayesTest {
def main(args:Array[String]): Unit = {
val conf = new SparkConf().setAppName("NaiveBayes").setMaster("local[2]")
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
val data = sc.textFile("file:///Users/walle/Documents/D3/sparkmlib/football.txt")
val parsedData = data.map{ line =>
val parts = line.split(',')
LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}
val splits = parsedData.randomSplit(Array(0.6, 0.4), seed = 11L)
val training = splits(0)
val test = splits(1)
val model = NaiveBayes.train(training, lambda = 1.0, modelType = "multinomial")
val predictionAndLabel = test.map(p => (model.predict(p.features), p.label))
val print_predict = predictionAndLabel.take(20)
for (i <- 0 to print_predict.length - 1){
println(print_predict(i)._1 + "\t" + print_predict(i)._2)
}
println("Predictionof (0.0, 2.0, 0.0, 1.0):"+model.predict(Vectors.dense(0.0,2.0,0.0,1.0)))
}
}
http://www.waitingfy.com/archives/4671
1. 数据
0,0 0 0 0 0,0 0 0 1 1,1 0 0 0 1,2 1 0 0 1,2 2 1 0 0,2 2 1 1 1,1 2 1 1 0,0 1 0 0 1,0 2 1 0 1,2 1 1 0 1,0 1 1 1 1,1 1 0 1 1,1 0 1 0 0,2 1 0 1
2. 输出
1.0 1.0 1.0 1.0 0.0 1.0 1.0 1.0 0.0 0.0 Predictionof (0.0, 2.0, 0.0, 1.0):0.0
4671
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网

本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Unix/Linux编程实践教程
Bruce Molay、杨宗源、黄海涛 / 杨宗源、黄海涛 / 清华大学出版社 / 2004-10-1 / 56.00元
操作系统是计算机最重要的系统软件。Unix操作系统历经了几十年,至今仍是主流的操作系统。本书通过解释Unix的工作原理,循序渐进地讲解实现Unix中系统命令的方法,让读者理解并逐步精通Unix系统编程,进而具有编制Unix应用程序的能力。书中采用启发式、举一反三、图示讲解等多种方法讲授,语言生动、结构合理、易于理解。每一章后均附有大量的习题和编程练习,以供参考。 本书适合作为高等院校计算机及......一起来看看 《Unix/Linux编程实践教程》 这本书的介绍吧!


