
机器翻译(MT,Machine Translation)就是采用人工智能将文本从一种语言自动翻译成另一种语言的过程。虽然我们的最终目标是创建一个能够通用的翻译系统,使全球以各种不同的语言为母语的用户都能畅快无阻地获取信息和沟通,但想要将这一愿景变成现实,还有很长的路要走。
目前使用的大多数机器翻译系统采用的都是双语模型,需要为每个语言对(language pair)和任务提供标注示例。然而,这样的模型不适合于训练数据量不够充足的语言。不同语言之中巨大的复杂性使得双语模型不可能扩展到实际应用中。
为了解决这个问题并开发一个通用的翻译器,机器翻译领域必须要有从双语到多语模型的过渡。在多语模型的机器翻译中,一个单一的翻译模型就可以被用来处理多种语言。

Meta(前 Facebook)AI 实验室近日公布的多语言模型为机器翻译带来了巨大提升,该多语言模型在测试中已经超过了目前市面上最好的并且经过专门训练的双语模型,并借此赢得了机器翻译大赛 WMT 2021 的冠军(该模型也被命名成 WMT 21)。该模型在测试中已被证明具有可靠的有效性,无论对应的语言是否有充足的训练资源。
该模型的有效性表明,要在资源丰富和资源不足的语言上取得优秀的性能表现,需要在三个方面取得进展:
- 大规模的数据挖掘
- 扩展模型的能力
- 基础设施
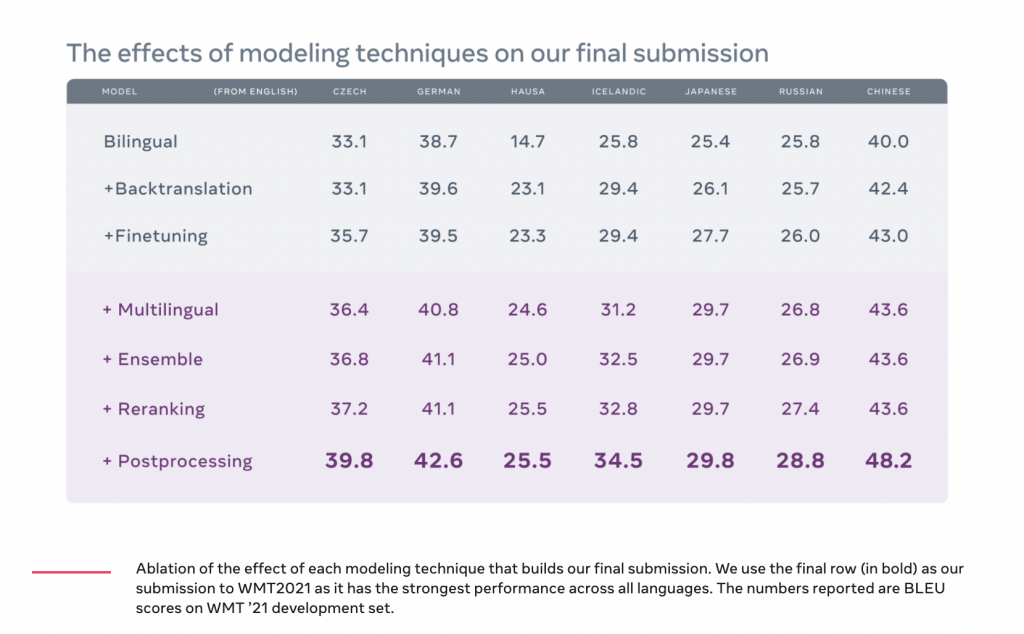
为了训练 WMT 2021 模型,研究人员设计了两种多语言方法:任意语言到英语,以及英语到任意语言。他们应用平行数据挖掘技术寻找翻译。
为了提高多语言模型设计的容量,模型规模从 150 亿个参数提高到 520 亿个,并在此基础之上利用 Facebook 最新的 GPU 内存节省解决方案 —— Fully Sharded Data-Parallel,将大规模训练的速度提升了 5 倍。
由于多语言模型会有容量上的竞争,因此必须在共享参数和不同语言的专业化之间取得平衡。如果都按比例扩大模型的大小就会导致不可持续的计算成本。为此 Meta 采用了一种新的方法,针对每个训练场景都只激活模型的一部分。
如上所述,WMT 21 的最大特点就是针对训练资源少,使用人群少的语言也同样具有有效性, 这也是机器翻译面临的最大挑战。目前这两个模型(任意语言到英语、英语到任意语言)都已发布至 GitHub PyTorch 仓库下,两个模型大小约为 25G。
