近日,谷歌 DeepMind 人工智能已进化到第四代,名为 MuZero,最突出的能力是无需提前学习规则就可以下棋玩游戏。
谷歌称 MuZero 可以未知环境中计划获胜策略,无需学习规则,便能掌握 Go(围棋), chess(国际象棋), shogi(日本将棋)和 Atari(电子游戏)。这和 MuZero 的前几代——AlphaGo,AlphaGo Zero,AlphaZero 有很大的区别。
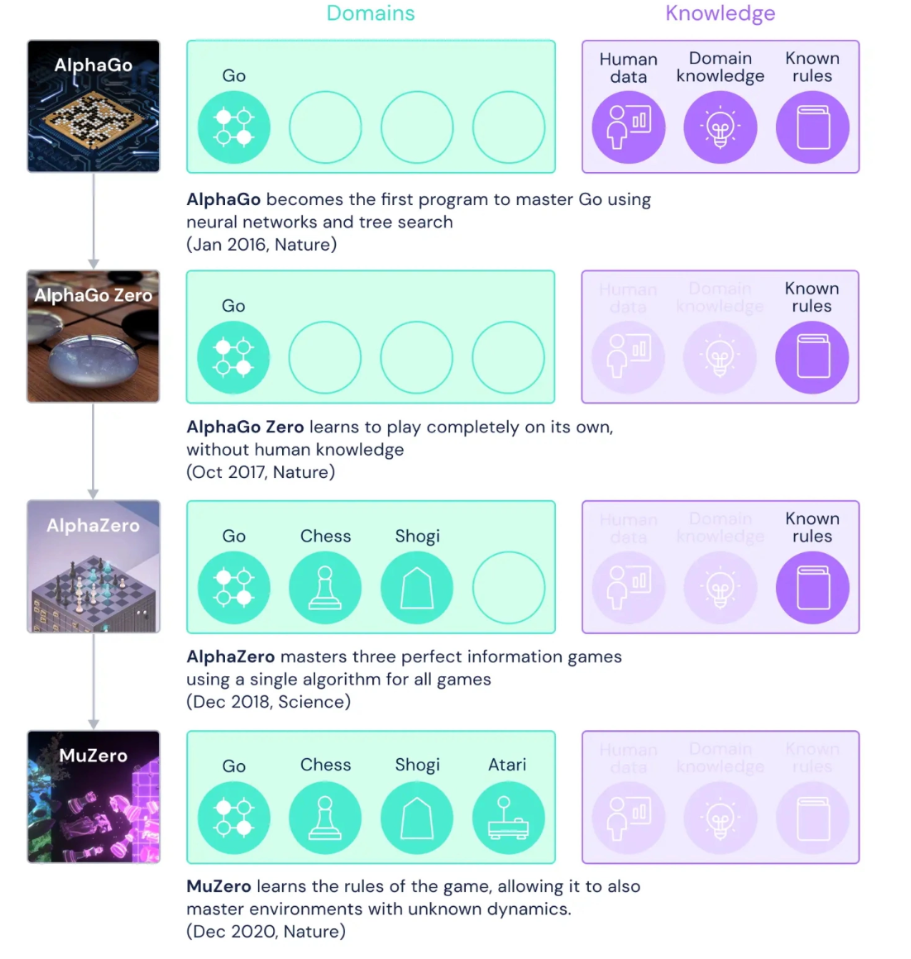
第一代 AlphaGo 早在 2016 年就可以击败世界围棋冠军,但需要先输入游戏规则和大量人类实战的数据进行训练。AlphaGo Zero 只需事先输入规则,无需学习人类实战的数据。到了第三代 AlphaZero,除了可以自主学会围棋,也通过事先了解规则,掌握了国际象棋和日本将棋。其原理是通过强大的前瞻性树搜索功能,基于超前搜索,依赖环境动态知识,如游戏规则或精确的模拟器来应对变化。但因为现实中的许多问题复杂且难以提炼简单规则,所以这种模型实际上很难被应用在更广泛的领域中。
MuZero 则是通过基于模型的计划来做决策,学习环境中的精确模型,并做出规划以解决问题。此外,MuZero 并没有尝试对整个环境建模,只是对代理商决策过程中的重要方面进行建模,以便在复杂要素环境中更快作出决策。其环境建模三要素为:
- The value: 当前位置的价值有多高?
- The policy: 采取哪种行动最好?
- The reward: 最后一个动作怎么样?
在谷歌的测试中,MuZero 在 Atari 游戏中的表现优于此前所有算法,并与 AlphaZero 在围棋,象棋和将棋上的超人类水平性能相匹配。
发布详情:https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
暂无回复。
