
WeChat TFCC 是微信技术架构部后台团队研发的服务端深度学习通用推理框架,也是腾讯深度学习与加速Oteam云帆的开源协同成果,具有高性能、易用、通用的特点,已在微信视频号、微信开放平台推荐系统、微信画像、微信智聆语音识别、语音合成等业务广泛使用; 支持81个ONNX Operation和108个Tensorflow Operation,覆盖推荐、NLP、语音等场景的各种主流模型,同时更多的Operation在持续接入中。
特性
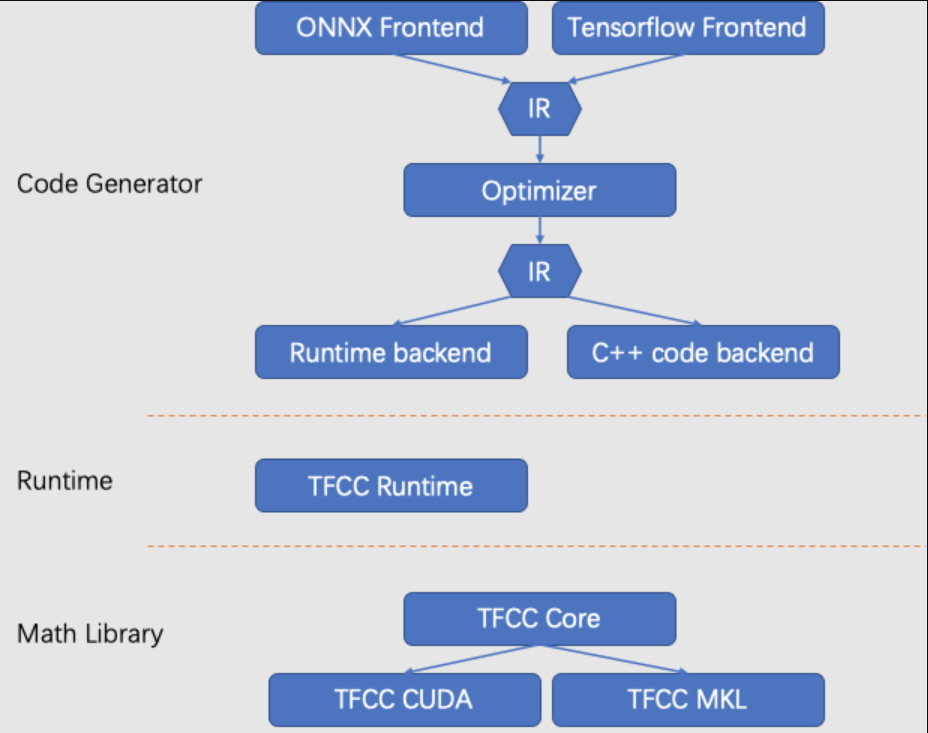
WeChat TFCC由Library、Runtime、Generator三大组件构成,通过层层抽象、互相配合的方式,在保证高性能的前提下,极大的提高了扩展性和通用性。
一、高性能
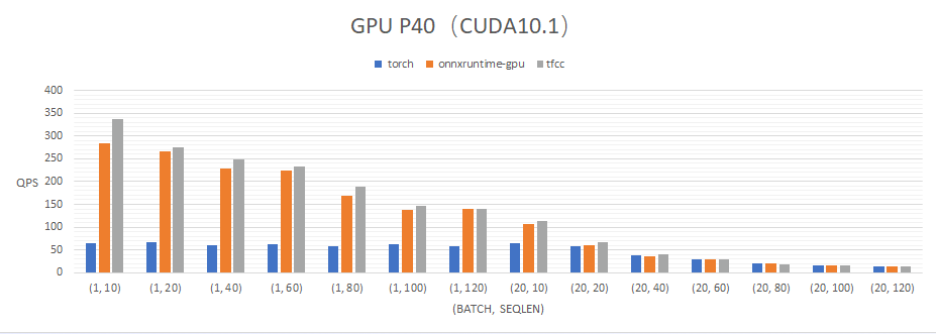
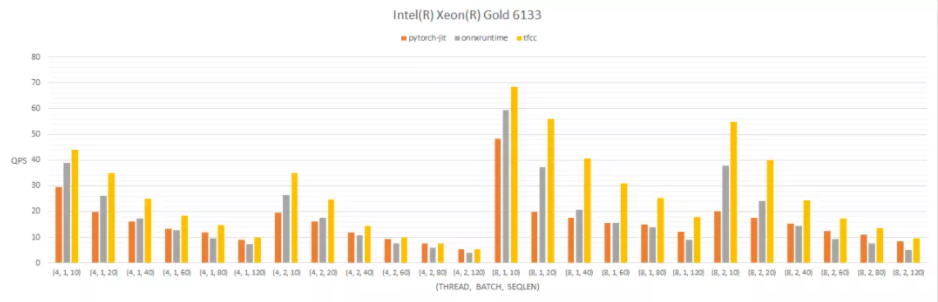
TFCC通过模型结构优化、常数跟踪、算子优化等多方面措施优化通用模型推理性能。下图是BERT(bert-base)模型下的QPS对比,可以看到TFCC在CPU/GPU的性能都处于较高水准。
模型结构优化
模型结构优化包含常数折叠、模型剪枝、算子融合等。常数折叠可以预先算好部分数据,减少线上运行时的计算量。模型剪枝是减少模型的无用分支,算子融合是将多个小算子融合成一个大算子,减少内存和显存的带宽压力。
常数跟踪
常数跟踪是指跟踪常量的走向,是比常量折叠更激进的优化方案,该方案可以对详细区分一个矩阵存在的局部常量,从而得到模型的更详细的信息,达到更好的模型结构优化效果。
算子优化
TFCC Math Library是TFCC底层的算子库,部分算子是对底层oneDNN及cublas的封装,部分则是经过汇编级优化的高性能算子。CPU支持使用AVX2、AVX512指令集加速运算。
二、易用性
TFCC提供了一套完善的工具,可以很方便的一条命令将ONNX模型和Tensorflow模型转化为TFCC模型,然后由Runtime动态读入图结构,并用JIT技术动态生成图调用链, 业务无需编写模型代码,即可将训练模型转换并部署高性能运行。
三、通用性
TFCC的通用性包含模型通用性和硬件通用型两个方面。
模型通用性
TFCC提供一套完善的工具,通过类编译器架构:Frontend->Optimizer->Backend结构,将ONNX模型和Tensorflow模型转换为统一的TFCC内部模型表示。当前支持81个ONNX Operation和108个Tensorflow Operation,覆盖推荐系统、NLP等场景的主流模型;由于使用类编译器架构,WeChat TFCC可以很方便的进行平行扩展,以支持更多种类更多模型。
硬件通用性
TFCC目前支持的硬件平台有X86-64平台的CPU及NVIDIA的GPU,切换平台只需要修改调用参数即可,并且基于不同平台的特点进行汇编级性能优化。
结语
TFCC专耕于服务端的深度学习推理,还在不断迭代中,后续会加入更多的特性及性能优化,敬请期待。
