
yadcc是广泛投产于腾讯广告后台的C++分布式编译系统。
我们在调研学习了业界的ccache、sccache、distcc、icecc等开源的编译加速系统之后,根据我们实际的工业生产场景,设计了这样一套系统。
目前我们实际生产环境:
- 有~1700编译核心;
- 使用512并发编译(实际并发度取决于本地预处理能力,32逻辑核以上可达到512并发);
- 每天编译产出(含命中分布式缓存)300,0000+个目标文件;
- 每天编译产出总计约3~5TB。
本着回馈社区的目的,我们现将这套分布式编译系统对外开源。
基本原理
与ccache、sccache、distcc、icecc等类似,可通过创建名为g++等的符号链接至yadcc的客户端,并将之加入PATH,来截获编译器调用。之后yadcc的客户端会将任务分发出去至编译机编译,降低本地负载。
也因此,通常而言,使用分布式编译可以加大本地并发度(因为单个任务很多时候是在休眠等待网络上的编译结果返回),实现更高的编译吞吐。例如8逻辑核的机器通常可以通过make -j100来加速编译。
需要注意的是,分布式编译通常只能提高吞吐,但是不能降低单个文件的编译耗时(暂不考虑命中缓存的情况)。对于无法并发编译的工程,除非命中缓存,否则分布式编译通常不能加快编译,反而可能有负面效果。
主要特点
我们首先分析了我们实际生产环境下的一些使用困难:
- 用户众多,如果没有中心节点统一调度并必要时阻塞新请求,则容易导致集群过载
- 需要某种方式可以便捷的下发、更新编译集群列表,降低运维成本
- 网络抖动、编译机由于各种原因离线等需要一定的容灾能力
- 多个用户(机器)在同一代码库工作,可能存在不必要的重复编译(如用户A提交了一个功能,用户B拉取代码编译)
- 新代码往往不能命中缓存,无条件查询分布式缓存会引入不必要的延迟
- 链接阶段会回落本地执行,如果不对并发度加以限制,大量本地链接容易导致过载或OOM死机
- 广告历来有更新编译器的传统,因此需要考虑新老过渡过程中多版本编译器共存
针对工业场景,我们主要作了如下一些优化:
- 我们加入了中心调度节点,所有请求均由调度节点统一分配,低负载时可允许客户端尽可能提交更多的任务,集群满载时可阻塞新请求避免过载。
- 中心的调度节点也避免了需要客户机感知编译集群的列表的需要,降低运维成本。
- 编译机向调度器定期心跳,这样我们不需要预先在调度器处配置编译机列表,降低运维成本。
- 我们使用本地守护进程和外界通信,这避免了每个客户端均反复进行TCP启动等操作,降低开销。
- 编译器wrapper会和本地守护进程通信,控制本地任务并发度避免本地过载。
- 分布式缓存避免不必要的重复编译。同时本地守护进程处会维护缓存的布隆过滤器,避免无意义的缓存查询引发不必要的网络延迟。
- 我们通过编译器哈希区分版本,这允许我们的集群中存在多个不同版本的编译器。(广告集群中同时存在GCC7/8/9/10)。
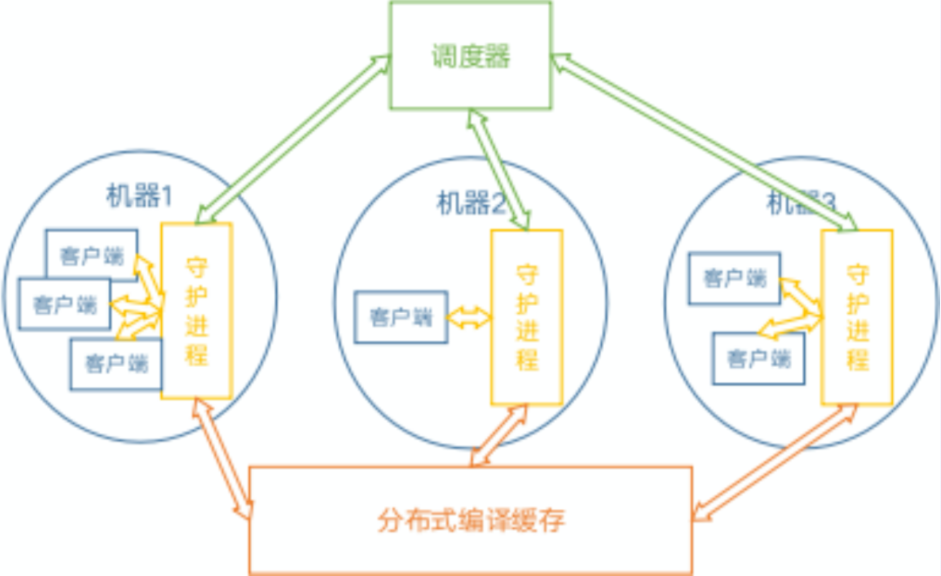
整体设计
我们的整体设计分为如下几部分:
- 调度器:具备全局视图,负责任务分发等;
- 编译缓存:全局共享,用于优化重复编译的场景;
- 守护进程:同时包含两种角色:
o 客户端本地守护进程,用于控制本地并发度、查询缓存、获取编译机、提交任务等;
o 编译机守护进程,用于接受网络上的任务,执行编译。
取决于实际部署,一台机器可能同时身兼两种职责,也可能只作为客户机或只作为编译机。
- 客户端wrapper:伪装成编译器,截获编译任务并通过yadcc分发出去进行分布式编译。
开源获取
Github地址:https://github.com/Tencent/yadcc
