内容简介:前言 Cloud Native KubeDL 是阿里开源的基于 Kubernetes 的 AI 工作负载管理框架,取自"Kubernetes-Deep-Learning"的缩写,希望能够依托阿里巴巴的场景,将大规模机器学习作业调度与管理的经验反哺社区。目前 Ku...

前言
Cloud Native
KubeDL 是阿里开源的基于 Kubernetes 的 AI 工作负载管理框架,取自"Kubernetes-Deep-Learning"的缩写,希望能够依托阿里巴巴的场景,将大规模机器学习作业调度与管理的经验反哺社区。目前 KubeDL 已经进入 CNCF Sandbox 项目孵化,我们会不断探索云原生 AI 场景中的最佳实践,助力算法科学家们简单高效地实现创新落地。
在最新的 KubeDL Release 0.4.0 版本中,我们带来了模型版本管理(ModelVersion)的能力,AI 科学家们可以像管理镜像一样轻松地对模型版本进行追踪,打标及存储。更重要的是,在经典的机器学习流水线中,“训练”与“推理”两个阶段相对独立,算法科学家视角中的“训练->模型->推理”流水线缺乏断层,而“模型”作为两者的中间产物正好能够充当那个“承前启后”的角色。
Github:https://github.com/kubedl-io/kubedl
网站:https://kubedl.io/model/intro/
模型管理现状
Cloud Native
模型文件是分布式训练的产物,是经过充分迭代与搜索后保留的算法精华,在工业界算法模型已经成为了宝贵的数字资产。通常不同的分布式框架会输出不同格式的模型文件,如 Tensorflow 训练作业通常输出 CheckPoint(.ckpt)、GraphDef(.pb)、SavedModel 等格式,而 PyTorch 则通常以 .pth 后缀,不同的框架会在加载模型时解析其中承载的运行时的数据流图、运行参数及其权重等信息,对于文件系统来说,它们都是一个(或一组)特殊格式的文件,就像 JPEG 和 PNG 格式的图像文件一样。
因此典型的管理方式就是把它们当作文件,托管在统一的对象存储中(如阿里云 OSS 和AWS S3),每个租户/团队分配一个目录,各自成员再把模型文件存储在自己对应的子目录中,由 SRE 来统一进行读写权限的管控:
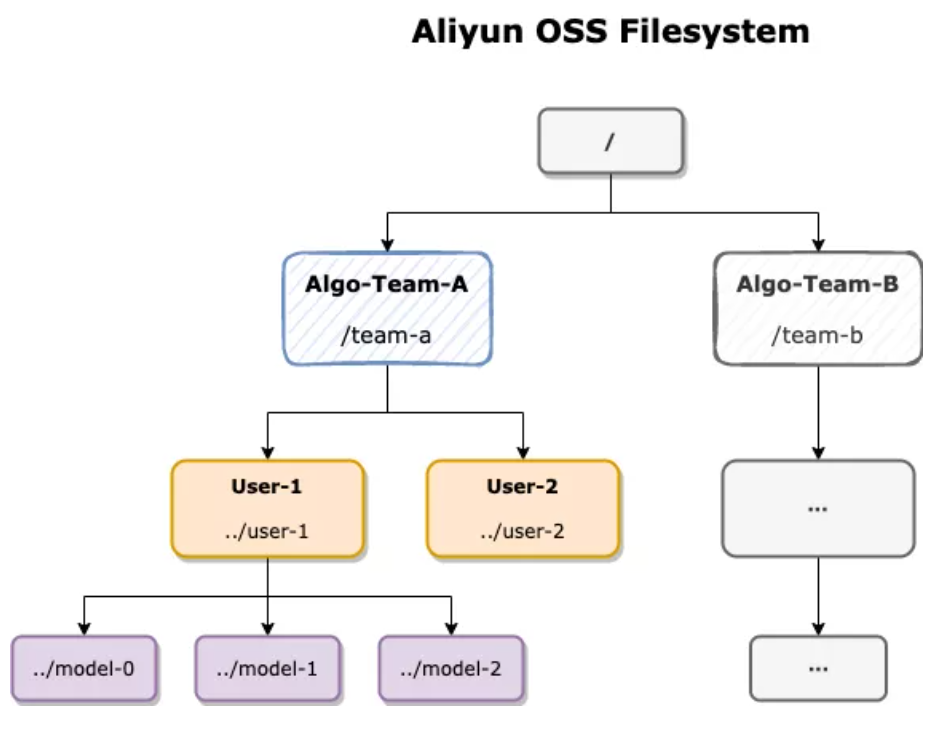
这种管理方式的优缺点都很明显:
- 好处是保留了用户的 API 使用习惯,在训练代码中将自己的目录指定为输出路径,之后将云存储的对应目录 mount 到推理服务的容器内加载模型即可;
- 但这对 SRE 提出了较高的要求,不合理的读写权限授权及误操作,可能造成文件权限泄露,甚至大面积的误删除;同时基于文件的管理方式不易实现模型的版本管理,通常要求用户自身根据文件名来标记,或是上层平台自己承担版本管理的复杂度;此外,模型文件与算法代码/训练参数的对应关系也无法直接映射,甚至同个文件在多次训练中会被多次覆写,难以追溯历史;
基于以上现状,KubeDL 充分结合了 Docker 镜像管理的优势,引入了一套 Image-Based 的镜像管理 API,让分布式训练和推理服务结合得更紧密自然,同时也极大简化了模型管理的复杂度。03
从镜像出发
Cloud Native
镜像(Image)是 Docker 的灵魂,也是容器时代的核心基础设施。镜像本身即分层的不可变文件系统,模型文件天然地可以作为其中的一个独立镜像层,两者结合的还会迸发出其他火花:
- 用户不用再面向文件管理模型,而是直接使用 KubeDL 提供的 ModelVersion API 即可,训练与推理服务之间通过 ModelVersion API 桥接;
- 与镜像一样,可以对模型打 Tag 实现版本追溯,并推送到统一的镜像 Registry 存储,通过 Registry 进行鉴权,同时镜像 Registry 的存储后端还可以替换成用户自己的 OSS/S3,用户可以平滑过渡;
- 模型镜像一旦构建完毕,即成为只读的模板,无法再被覆盖及篡写,践行 Serverless “不可变基础设施” 的理念;
- 镜像层(Layer)通过压缩算法及哈希去重,减少模型文件存储的成本并加快了分发的效率;
在“模型镜像化”的基础上,还可以充分结合开源的镜像管理组件,最大化镜像带来的优势:
- 大规模的推理服务扩容场景中,可以通过 Dragonfly 来加速镜像分发效率,面对流量突发型场景时可以快速弹出无状态的推理服务实例,同时避免了挂载云存储卷可能出现的大规模实例并发读时的限流问题;
- 日常的推理服务部署,也可以通过 OpenKruise 中的 ImagePullJob 来提前对节点上的模型镜像进行预热,提升扩容发布的效率。
Model 与 ModelVersion
Cloud Native
KubeDL 模型管理引入了 2 个资源对象:Model 及 ModelVersion,Model 代表某个具体的模型,ModelVersion 则表示该模型迭代过程中的一个具体版本,一组 ModelVersion 从同一个 Model 派生而来。以下是示例:
apiVersion: model.kubedl.io/v1alpha1kind: ModelVersionmetadata:name: my-mvnamespace: defaultspec:# The model name for the model versionmodelName: model1# The entity (user or training job) that creates the modelcreatedBy: user1# The image repo to push the generated modelimageRepo: modelhub/resnetimageTag: v0.1# The storage will be mounted at /kubedl-model inside the training container.# Therefore, the training code should export the model at /kubedl-model path.storage:# The local storage to store the modellocalStorage:# The local host path to export the modelpath: /foo# The node where the chief worker run to export the modelnodeName: kind-control-plane# The remote NAS to store the modelnfs:# The NFS server addressserver: ***.cn-beijing.nas.aliyuncs.com# The path under which the model is storedpath: /foo# The mounted path inside the containermountPath: /kubedl/models---apiVersion: model.kubedl.io/v1alpha1kind: Modelmetadata:name: model1spec:description: "this is my model"status:latestVersion:imageName: modelhub/resnet:v1c072modelVersion: mv-3
Model 资源本身只对应某类模型的描述,并追踪最新的版本的模型及其镜像名告知给用户,用户主要通过 ModelVersion 来自定义模型的配置:
- modelName:用来指向对应的模型名称;
- createBy:创建该 ModelVersion 的实体,用来追溯上游的生产者,通常是一个分布式训练作业;
- imageRepo:镜像 Registry 的地址,构建完成模型镜像后将镜像推送到该地址;
- storage:模型文件的存储载体,当前我们支持了 NAS,AWSEfs 和 LocalStorage 三种存储介质,未来会支持更多主流的存储方式。以上的例子中展示了两种模型输出的方式(本地存储卷和 NAS 存储卷),一般只允许指定一种存储方式。
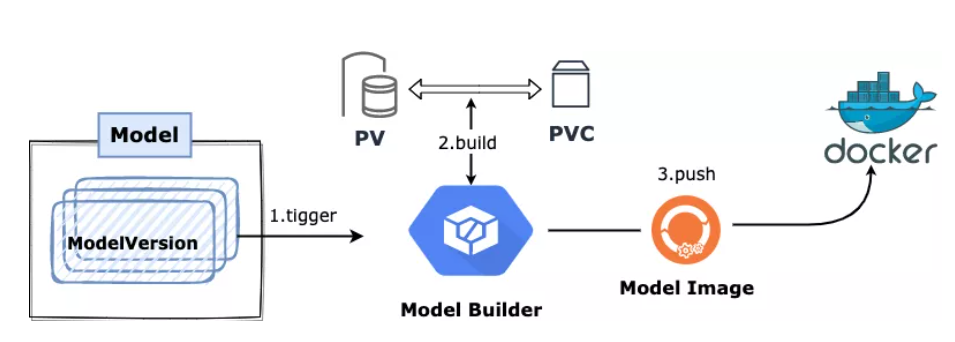
当 KubeDL 监听到 ModelVersion 的创建时,便会触发模型构建的工作流:
-
监听 ModelVersion 事件,发起一次模型构建;
<p style="margin-left:0; margin-right:0; text-align:left"> </li> <li> <p style="margin-left:0; margin-right:0; text-align:left"><span>根据 storage 的类型创建出对应的 PV 与 PVC 并等待 volume 就绪;</span> <p style="margin-left:0; margin-right:0; text-align:left"> </li> <li> <p style="margin-left:0; margin-right:0; text-align:left"><span>创建出 Model Builder 进行用户态的镜像构建,Model Builder 我们采用了 kaniko 的方案,其构建的过程与镜像格式,和标准的 Docker 完全一致,只不过这一切都在用户态发生,不依赖任何宿主机的 Docker Daemon;</span> <p style="margin-left:0; margin-right:0; text-align:left"> </li> <li> <p style="margin-left:0; margin-right:0; text-align:left"><span>Builder 会从 volume 的对应路径中拷贝出模型文件(可以是单文件也可以是一个目录),并将其作为独立的镜像层来构建出一个完整的 Model Image;</span> <p style="margin-left:0; margin-right:0; text-align:left"> </li> <li> <p style="margin-left:0; margin-right:0; text-align:left"><span>把产出的 Model Image 推送到 ModelVersion 对象中指定的镜像 Registry 仓库;</span> <p style="margin-left:0; margin-right:0; text-align:left"> </li> <li> <p style="margin-left:0; margin-right:0; text-align:left"><span>结束整个构建过程;</span> </li>
至此,该 ModelVersion 对应版本的模型便固化在了镜像仓库中,可以分发给后续的推理服务进行消费。
从训练到模型
Cloud Native
虽然 ModelVersion 支持独立创建并发起构建,但我们更期望在分布式训练作业成功结束后自动触发模型的构建,天然串联成一个流水线。
KubeDL 支持这种提交方式,以 TFJob 作业为例,在发起分布式训练时即指定好模型文件的输出路径和推送的仓库地址,当作业成功执行完毕时就会自动创建出一个 ModelVersion 对象,并将 createdBy 指向上游的作业名,而当作业执行失败或提前终止时并不会触发 ModelVersion 的创建。
以下是一个分布式 mnist 训练的例子,其将模型文件输出到本地节点的 /models/model-example-v1 路径,当顺利运行结束后即触发模型的构建:
apiVersion: "training.kubedl.io/v1alpha1"kind: "TFJob"metadata:name: "tf-mnist-estimator"spec:cleanPodPolicy: None# modelVersion defines the location where the model is stored.modelVersion:modelName: mnist-model-demo# The dockerhub repo to push the generated imageimageRepo: simoncqk/modelsstorage:localStorage:path: /models/model-example-v1mountPath: /kubedl-modelnodeName: kind-control-planetfReplicaSpecs:Worker:replicas: 3restartPolicy: Nevertemplate:spec:containers:- name: tensorflowimage: kubedl/tf-mnist-estimator-api:v0.1imagePullPolicy: Alwayscommand:- "python"- "/keras_model_to_estimator.py"- "/tmp/tfkeras_example/" # model checkpoint dir- "/kubedl-model" # export dir for the saved_model format
% kubectl get tfjobNAME STATE AGE MAX-LIFETIME MODEL-VERSIONtf-mnist-estimator Succeeded 10min mnist-model-demo-e7d65% kubectl get modelversionNAME MODEL IMAGE CREATED-BY FINISH-TIMEmnist-model-demo-e7d65 tf-mnist-model-example simoncqk/models:v19a00 tf-mnist-estimator 2021-09-19T15:20:42Z% kubectl get poNAME READY STATUS RESTARTS AGEimage-build-tf-mnist-estimator-v19a00 0/1 Completed 0 9min
通过这种机制,还可以将其他“仅当作业执行成功才会输出的 Artifacts 文件”一起固化到镜像中,并在后续的阶段中使用。
从模型到推理
Cloud Native
有了前面的基础,在部署推理服务时直接引用已构建好的 ModelVersion,便能加载对应模型并直接对外提供推理服务。至此,算法模型生命周期(代码->训练->模型->部署上线)各阶段通过模型相关的 API 联结了起来。
通过 KubeDL 提供的 Inference 资源对象部署一个推理服务时,只需在某个 predictor 模板中填充对应的 ModelVersion 名,Inference Controller 在创建 predictor 时会注入一个 Model Loader,它会拉取承载了模型文件的镜像到本地,并通过容器间共享 Volume 的方式把模型文件挂载到主容器中,实现模型的加载。如上文所述,与 OpenKruise 的 ImagePullJob 相结合我们能很方便地实现模型镜像预热,来为模型的加载提速。为了用户感知的一致性,推理服务的模型挂载路径与分布式训练作业的模型输出路径默认是一致的。
apiVersion: serving.kubedl.io/v1alpha1kind: Inferencemetadata:name: hello-inferencespec:framework: TFServingpredictors:- name: model-predictor# model built in previous stage.modelVersion: mnist-model-demo-abcdereplicas: 3batching:batchSize: 32template:spec:containers:- name: tensorflowargs:- --port=9000- --rest_api_port=8500- --model_name=mnist- --model_base_path=/kubedl-model/command:- /usr/bin/tensorflow_model_serverimage: tensorflow/serving:1.11.1imagePullPolicy: IfNotPresentports:- containerPort: 9000- containerPort: 8500resources:limits:cpu: 2048mmemory: 2Girequests:cpu: 1024mmemory: 1Gi
对于一个完整的推理服务,可能同时 Serve 多个不同模型版本的 predictor,比如在常见搜索推荐的场景中,期望以 A/B Testing 实验来同时对比多次模型迭代的效果,通过 Inference+ModelVersion 可以很容易做到。我们对不同的 predictor 引用不同版本的模型,并分配合理权重的流量,即可达到一个推理服务下同时 Serve 不同版本的模型并灰度比较效果的目的:
apiVersion: serving.kubedl.io/v1alpha1kind: Inferencemetadata:name: hello-inference-multi-versionsspec:framework: TFServingpredictors:- name: model-a-predictor-1modelVersion: model-a-version1replicas: 3trafficWeight: 30 # 30% traffic will be routed to this predictor.batching:batchSize: 32template:spec:containers:- name: tensorflow// ...- name: model-a-predictor-2modelVersion: model-version2replicas: 3trafficWeight: 50 # 50% traffic will be roted to this predictor.batching:batchSize: 32template:spec:containers:- name: tensorflow// ...- name: model-a-predictor-3modelVersion: model-version3replicas: 3trafficWeight: 20 # 20% traffic will be roted to this predictor.batching:batchSize: 32template:spec:containers:- name: tensorflow// ...

总结
Cloud Native
KubeDL 通过引入 Model 和 ModelVersion 两种资源对象,与标准的容器镜像相结合实现了模型构建,打标与版本追溯,不可变存储与分发等功能,解放了粗放型的模型文件管理模式,镜像化还可以与其他优秀的开源社区相结合,实现镜像分发加速,模型镜像预热等功能,提升模型部署的效率。同时,模型管理 API 的引入很好地连接了分布式训练与推理服务两个原本割裂的阶段,显著提升了机器学习流水线的自动化程度,以及算法科学家上线模型、实验对比的体验和效率。我们欢迎更多的用户试用 KubeDL,并向我们提出宝贵的意见,也期待有更多的开发者关注以及参与 KubeDL 社区的建设!
KubeDL Github 地址:https://github.com/kubedl-io/kubedl
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,也希望大家多多支持 码农网

本站部分资源来源于网络,本站转载出于传递更多信息之目的,版权归原作者或者来源机构所有,如转载稿涉及版权问题,请联系我们。

Django 1.0 Template Development
Scott Newman / Packt / 2008 / 24.99
Django is a high-level Python web application framework designed to support the rapid development of dynamic websites, web applications, and web services. Getting the most out of its template system a......一起来看看 《Django 1.0 Template Development》 这本书的介绍吧!


